Master the shift from manual Spark tuning to AI-driven architecture. Learn how Gemini-assisted workflows optimize performance, reduce latency, and ensure scalability.
Your Apache Spark job just failed. It isn’t a syntax error; it is a massive data skew that your manual partitioning strategy failed to catch. You spend the next four hours digging through executor logs, tweaking spark.sql.shuffle.partitions, and hoping the JVM gods are in your favor.
This is the “Operator” trap. You are treating distributed computing like a manual transmission car, shifting gears while the industry pivots toward an Autopilot model . We are transitioning from operators who tune individual parameters to architects who oversee intelligent, self-optimizing systems .
The Great Divide: Deterministic vs. Probabilistic Optimization
Traditional optimization is built on certainty. It thrives in environments like logistics or finance where constraints are hard-coded and problems are well-defined . You know your memory limits, you understand your disk I/O, and you rely on static rules to govern performance.
AI-driven optimization operates on a different paradigm. It is designed for high-cardinality complexity—such as healthcare analytics or marketing automation—where variables are too numerous for a human to map manually , .
| Feature | Traditional Spark Tuning | AI-Driven Optimization |
|---|---|---|
| Approach | Deterministic / Rule-based | Probabilistic / Data-driven |
| Primary Task | Manual Parameter Tuning | Automated Pattern Recognition |
| Complexity Handling | Low (Requires human expertise) | High (Handles non-linear variables) |
| Workflow | Reactive (Fix after failure) | Predictive (Anticipate bottlenecks) |
In a traditional setup, you are manually selecting algorithms, preprocessing data, and tuning hyperparameters. It is slow, tedious, and prone to human error . AI-driven systems utilize predictive modeling to anticipate bottlenecks before they manifest in your production environment .
The Rise of the Self-Healing Data Pipeline
We are witnessing a profound convergence of Generative AI and database management . We are moving beyond simple chatbots toward self-healing databases that detect and resolve performance issues without a human touching a configuration file , .
By integrating Large Language Models (LLMs) into the data lifecycle, we achieve several critical advancements:
- Predictive Data Modeling: Anticipating future storage and processing needs before the cluster hits a resource bottleneck .
- Automated Hyperparameter Tuning: Using AutoML to transform raw data into optimized features by automating intermediate processing stages .
- Schema-Aware SQL Generation: Converting plain-English requests into precise, optimized SQL that respects your specific table constraints .
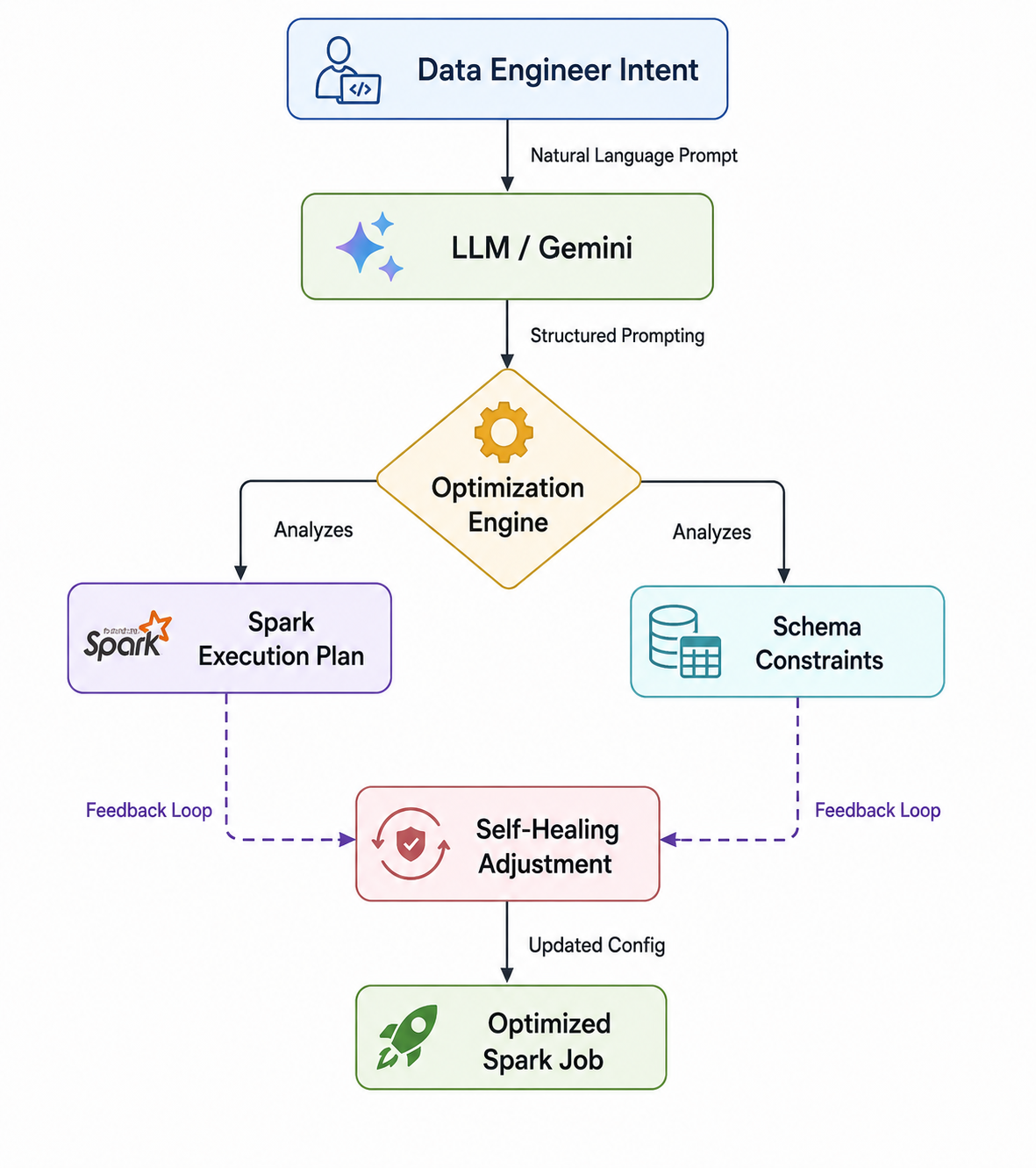
graph TD
A[Data Engineer Intent] -->|Natural Language Prompt| B(LLM / Gemini)
B -->|Structured Prompting| C{Optimization Engine}
C -->|Analyzes| D[Spark Execution Plan]
C -->|Analyzes| E[Schema Constraints]
D -->|Feedback Loop| F[Self-Healing Adjustment]
E -->|Feedback Loop| F
F -->|Updated Config| G[Optimized Spark Job]
Alt text: A flowchart showing the AI-assisted tuning loop, where human intent and system logs feed into an LLM to produce optimized Spark configurations.
Mastering Gemini Prompt Engineering for Spark Tuning
If you want to use an LLM to optimize your Apache Spark performance, you cannot simply ask it to “make my job faster.” That is a low-fidelity prompt that yields generic, often dangerous results . To get high-quality outputs, you must move toward structured frameworks.
The “Role + Context + Task + Format” Framework
This is the gold standard for ensuring the LLM does not hallucinate non-existent Spark configurations.
- Role: Define the persona (e.g., “Senior Distributed Systems Engineer”).
- Context: Provide the environment specifics (e.g., “Spark 3.5 on EMR r5.xlarge”).
- Task: Clearly define the objective (e.g., “Mitigate OOM errors during shuffle”).
- Format: Specify the output structure (e.g., “JSON object with ‘rationale’ and ‘configs'”).
The SI -> RI -> QI Structure
For high-stakes, iterative automation, use the SI -> RI -> QI structure to maintain consistency. This framework ensures the model has the necessary data to provide valid technical advice .
- System Instruction (SI): High-level behavioral guardrails that define the model’s expertise as a Spark performance tuning agent.
- Reference Information (RI): The raw technical data, including schema definitions, execution plans, and historical error logs.
- Query Instruction (QI): The specific, actionable request for optimization based on the provided RI.
Building an AI-Assisted Tuning Loop
To move from “Operator” to “Architect,” you must build orchestration layers that treat the LLM as a recommendation engine . [Internal Link: Suggestion: See our guide on MLOps integration for Spark].
Step 1: Capture the Spark Log
Extract the stderr or the Spark UI execution plan in JSON format where the bottleneck occurs.
Step 2: Construct the Structured Prompt
Feed the execution plan into the LLM using the SI-RI-QI structure. Ensure the context includes memory settings and partition counts.
Step 3: Implementation Example
The following Python snippet demonstrates how to wrap a Gemini API call to suggest optimizations based on a simulated Spark error.
import google.generativeai as genai
def optimize_spark_job(log_data, schema_info):
"""
Simulates an AI-driven optimization agent using Gemini.
"""
genai.configure(api_key="YOUR_GEMINI_API_KEY")
model = genai.GenerativeModel('gemini-pro')
# SI -> RI -> QI Structure
system_instruction = "You are a specialized Spark Performance Tuning Agent."
reference_info = f"SCHEMA: {schema_info}\nLOG_DATA: {log_data}"
query_instruction = "Identify the bottleneck. Suggest three Spark config changes."
prompt = f"{system_instruction}\n\n{reference_info}\n\n{query_instruction}"
response = model.generate_content(prompt)
return response.text
# Execution
mock_log = "Stage 2: Shuffle Read Failure: Executor lost due to OOM"
print(optimize_spark_job(mock_log, "Table 'sales' partitioned by 'region'"))
Alt text: Python code block demonstrating the use of the Google Generative AI SDK to process Spark logs and return optimization suggestions.
The Skeptic’s Corner: Mitigating Technical Debt
Most “AI-driven architect” hype carries significant risk. We are building layers of abstraction that can become impossible to debug when they fail. When you allow an LLM to automate your hyperparameter tuning, you introduce non-determinism . An automated fix might resolve a latency issue today but cause a massive data skew or a catastrophic spike in cloud billing tomorrow.
If you adopt these tools, implement strict guardrails. Treat the AI as a recommendation engine, not an autonomous execution engine . Your role is to monitor the systems that fly the plane, ensuring the autopilot hasn’t diverged from your business requirements.
Conclusion: The Future of Data Engineering
The transition toward AI-augmented database management is inevitable. By mastering the SI-RI-QI framework and treating AI as a partner in architectural design, engineers can focus on higher-level logic while leaving the tedious task of parameter tuning to intelligent systems.
FAQ
Q: Does the compute saved by AI optimization outweigh the token cost of the LLM?
A: In most high-scale environments, yes. The cost of a few thousand tokens is negligible compared to the cost of over-provisioned clusters or the man-hours required for manual debugging .
Q: How do we maintain auditability in a self-healing database?
A: You must log the “reasoning” output from the LLM alongside the applied configuration changes. This creates an audit trail that explains why a change was made, which is critical for compliance .
Q: What are the risks of using AutoML in regulated industries like finance?
A: The primary risk is “black-box” behavior. In regulated sectors, you must ensure that AI-driven changes are explainable and that they do not violate data sovereignty or fairness constraints .
Q: Can I use this approach for non-Spark databases?
A: Absolutely. The SI-RI-QI framework is model-agnostic and can be adapted for any database system where you can extract execution plans and schema metadata .