The evolution of Retrieval-Augmented Generation (RAG) represents a paradigm shift from static indexing toward dynamic orchestration. While early implementations relied on linear retrieval patterns, modern enterprise requirements have driven the industry toward sophisticated, decision-making architectures capable of self-correction and multi-step reasoning.
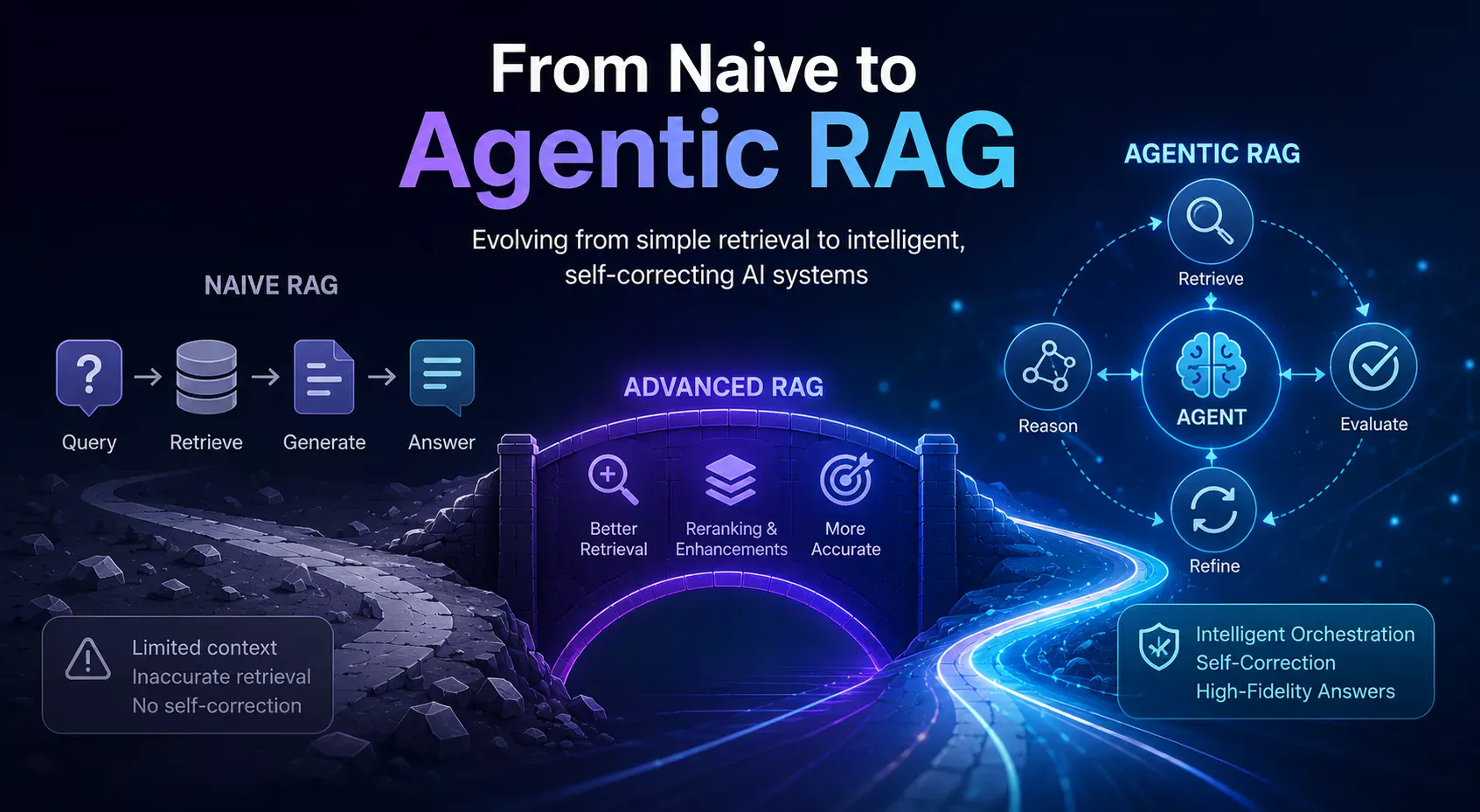
The Limitations of Vanilla RAG
Initial RAG implementations typically followed a “Vanilla” pattern: chunking documents, generating embeddings, and performing a top-$k$ search via cosine similarity. This approach often faces significant challenges in complex enterprise environments due to two primary factors:
1. Structural Blindness
Vanilla pipelines often treat data as flat text, which can strip away the hierarchical logic of a document. In a standard recursive text splitter setup, the relationship between a section header and its sub-bullets—or a table and its caption—can be lost. When a query requires specific structural context, a naive retriever may fetch chunks that are semantically similar but logically misplaced within the document’s hierarchy.
2. Retrieval Inaccuracy
A naive pipeline lacks a mechanism to evaluate whether retrieved chunks actually satisfy the user’s query. Because these systems rely on mathematical proximity in vector space, semantic similarity does not always equate to factual relevance. For example, a query regarding “the impact of interest rate hikes on mortgage applications” might retrieve general information about interest rates without capturing the specific causal relationship requested. Furthermore, simply using a more powerful LLM to improve reasoning does not solve the underlying issue if the retrieved context itself is irrelevant.
The Advanced RAG Bridge
Before transitioning to fully autonomous agents, enterprise pipelines typically adopt Advanced RAG techniques to fix these foundational flaws. These optimizations focus on enhancing both pre-retrieval and post-retrieval steps:
- Query Transformation: Users rarely phrase queries perfectly for vector search. Techniques like HyDE (Hypothetical Document Embeddings) use an LLM to generate a hypothetical ideal answer, then embed that answer to search the vector space. This effectively bridges the vocabulary gap between short user queries and long technical documents.
- Parent-Child Chunking: To solve structural blindness, developers split documents into small “child” chunks for highly precise vector matching, but pass the larger surrounding “parent” context to the LLM. This ensures the model sees the broader document logic without sacrificing search precision.
- Post-Retrieval Re-ranking: Vector similarity often retrieves documents that are “semantically close” but not “answer-relevant.” A Cross-Encoder Re-ranker (such as Cohere Rerank or FlashRank) acts as a second-pass filter, scoring and reordering the initial top-$k$ chunks based on true contextual relevance before they reach the LLM.
The Agentic Shift: Orchestration and Loops
The move toward Agentic RAG replaces linear pipelines with cyclical, decision-driven workflows. Instead of a straight line from Query $\rightarrow$ Retrieve $\rightarrow$ Generate, these systems implement an orchestration layer—often using frameworks like LangGraph—that treats retrieval as a tool to be utilized by an intelligent agent.
State Management: The Brain of the Agent
The defining feature of orchestration frameworks like LangGraph is State Management. In a Corrective RAG (CRAG) or Self-RAG loop, the system must “remember” what it has already tried. LangGraph utilizes a state machine architecture where the state (e.g., the original query, retrieved chunks, and evaluation scores) is passed between nodes. If a retrieval evaluator grades a chunk as irrelevant, the state is updated, triggering an edge transition to a query transformation node or a fallback web search, rather than starting the process over from scratch.
The following diagram illustrates the workflow of an agentic architecture:
sequenceDiagram
participant U as User Query
participant A as Agentic Controller (LangGraph)
participant C as Classifier/Router
participant R as Specialized Retrievers (Graph/Hybrid/Multi-source)
participant L as LLM Reasoner
U->>A: Submit Query
A->>C: Classify Intent & Source Needs
C-->>A: Return Strategy (e.g., Graph vs Vector)
A->>R: Execute Targeted Retrieval
R-->>A: Return Context/Chunks
A->>L: Evaluate Relevance (Self-RAG Logic)
alt Context Irrelevant
L-->>A: Trigger Corrective RAG Loop
A->>R: Re-query with Refined Parameters
else Context Valid
L-->>A: Generate Final Response
end
A->>U: Deliver High-Fidelity Output
The Evolutionary Roadmap of RAG Architectures
To address specific failure modes, the industry has developed several specialized archetypes that represent a progression in complexity:
| Architecture Type | Primary Strength | Technical Mechanism |
|---|---|---|
| Vanilla RAG | Low Latency / Simplicity | Linear: Query $\rightarrow$ Vector Search $\rightarrow$ LLM |
| Advanced RAG | Retrieval Precision | Pipeline Additions: HyDE, Parent-Child chunking, and Re-ranking. |
| Self-RAG | Self-Correction | Iterative: LLM generates special tokens to critique both retrieved passages and its own output. |
| Corrective RAG (CRAG) | Error Mitigation | Feedback Loop: Evaluates context relevance; triggers query refinement or web search fallback. |
| Graph RAG | Relationship Mapping | Knowledge Graphs: Traverses nodes/edges to connect multi-hop entities. |
| Agentic RAG | Dynamic Decision Making | Orchestration: LangGraph state machines route queries to specialized tools based on intent. |
| Multi-Agent RAG | Specialized Collaboration | Distributed Intelligence: Multiple specialized agents collaborate on a single goal. |
Key Technical Distinctions
Graph RAG vs. Vector Search
While Vanilla RAG relies on concept proximity, Graph RAG focuses on connections. In environments with highly relational data, Graph RAG maps entities as nodes and relationships as edges, allowing the retriever to traverse the graph to find multi-hop connections that are often missed by standard cosine similarity.
The Self-Correction Loop
Self-RAG and Corrective RAG introduce an evaluation step between retrieval and generation. If the LLM Reasoner determines that the retrieved context is insufficient, it triggers a corrective loop to refine the query parameters and re-invoke the retriever, rather than proceeding with irrelevant data.
Hybrid RAG: Precision via Keyword Matching
In scenarios involving technical jargon or specific product IDs, semantic search may fail. Hybrid RAG mitigates this by combining dense embeddings with sparse keyword retrieval (such as BM25), ensuring that exact matches are prioritized alongside semantic meaning.
Implementation and Resource Tradeoffs
The transition to these advanced architectures involves significant shifts in how computational resources are utilized:
- Compute vs. Memory: Agentic RAG shifts the burden from memory-heavy static indexing toward compute-heavy dynamic reasoning. Higher CPU/GPU cycles are consumed by decision-making logic (e.g., LangGraph) to reduce the need for massive, redundant vector storage.
- Latency vs. Throughput: Advanced architectures like Self-RAG or Multi-Agent RAG increase per-query latency due to iterative loops and multi-step reasoning, sacrificing real-time throughput for higher precision.
- Evaluation Frameworks: Transitioning to advanced architectures requires rigorous evaluation. Because Agentic RAG introduces non-deterministic, multi-step loops, traditional LLM metrics fall short. The industry relies on specialized evaluation frameworks—such as RAGAS and TruLens—to measure pipelines across the “RAG Triad”:
- Context Precision: Did the retriever fetch the right information?
- Faithfulness: Is the final answer entirely grounded in the retrieved context, or did the LLM hallucinate?
- Answer Relevance: Does the final output directly address the user’s initial query?
For Enterprise Data Engineers, these advancements introduce increased operational complexity, requiring the management of heterogeneous latency patterns and reliability across diverse, multi-source pipelines.
The release of Agentic RAG for Dummies v2.0 serves as an open-source bridge to help developers move from basic RAG tutorials toward extensible, agent-driven systems using LangGraph.